What is ETL Pipeline? A Comprehensive Guide to Understanding ETL

In today’s data-driven world, the ability to efficiently manage and process large volumes of data is crucial for any business aiming to make informed decisions. This is where ETL
pipelines come into play. ETL, which stands for Extract, Transform, Load, is a process that ensures data is accurately collected, transformed into a usable format, and loaded into a destination system. This comprehensive guide will walk you through the intricacies of ETL pipelines, their importance, how they work, and how you can implement them in your data management strategy.
- What is ETL?
- What is an ETL Pipeline?
- How Does an ETL Pipeline Work?
- Benefits of ETL Pipeline: Why ETL Pipelines are Essential?
- Components of an ETL Pipeline
- Different Types of ETL Pipelines
- Characteristics of an ETL Pipeline
- Building an ETL Pipeline: Step-by-Step Guide
- ETL Pipeline Best Practices
- Common Challenges in ETL Pipelines
- Top ETL Tools in the Industry
- Real-World ETL Pipeline Use Cases
- Future of ETL: Trends and Innovations
- FAQs about ETL Pipeline
- Conclusion
- Optimize Your Data Flow with BuzzyBrains’ ETL Solutions!
What is ETL?
ETL, an acronym for Extract, Transform, Load, is a fundamental process in the field of data management. It involves extracting data from various sources, transforming it into a format suitable for analysis, and loading it into a target system, such as a data warehouse. This process allows organizations to consolidate data from multiple sources, ensuring that it is clean, organized, and ready for business intelligence or analytics.
ETL processes have become the backbone of data warehousing and business intelligence, enabling companies to make data-driven decisions with confidence. By automating the extraction, transformation, and loading of data, ETL pipelines ensure that businesses have access to accurate and up-to-date information, thereby enhancing their ability to respond to market changes and customer needs.
What is an ETL Pipeline?
An ETL pipeline refers to the automated workflow that executes the ETL process. It is a sequence of processes that extracts data from various sources, transforms it according to predefined rules, and loads it into a destination system. The pipeline ensures that data moves smoothly from its source to its destination, undergoing necessary transformations to make it useful for end-users.
ETL pipelines can vary in complexity depending on the data sources, transformation rules, and the target system. They can handle structured data from databases, semi-structured data from APIs, and even unstructured data from logs or documents. The primary goal of an ETL pipeline is to streamline the flow of data, ensuring that it is accurate, timely, and ready for analysis.
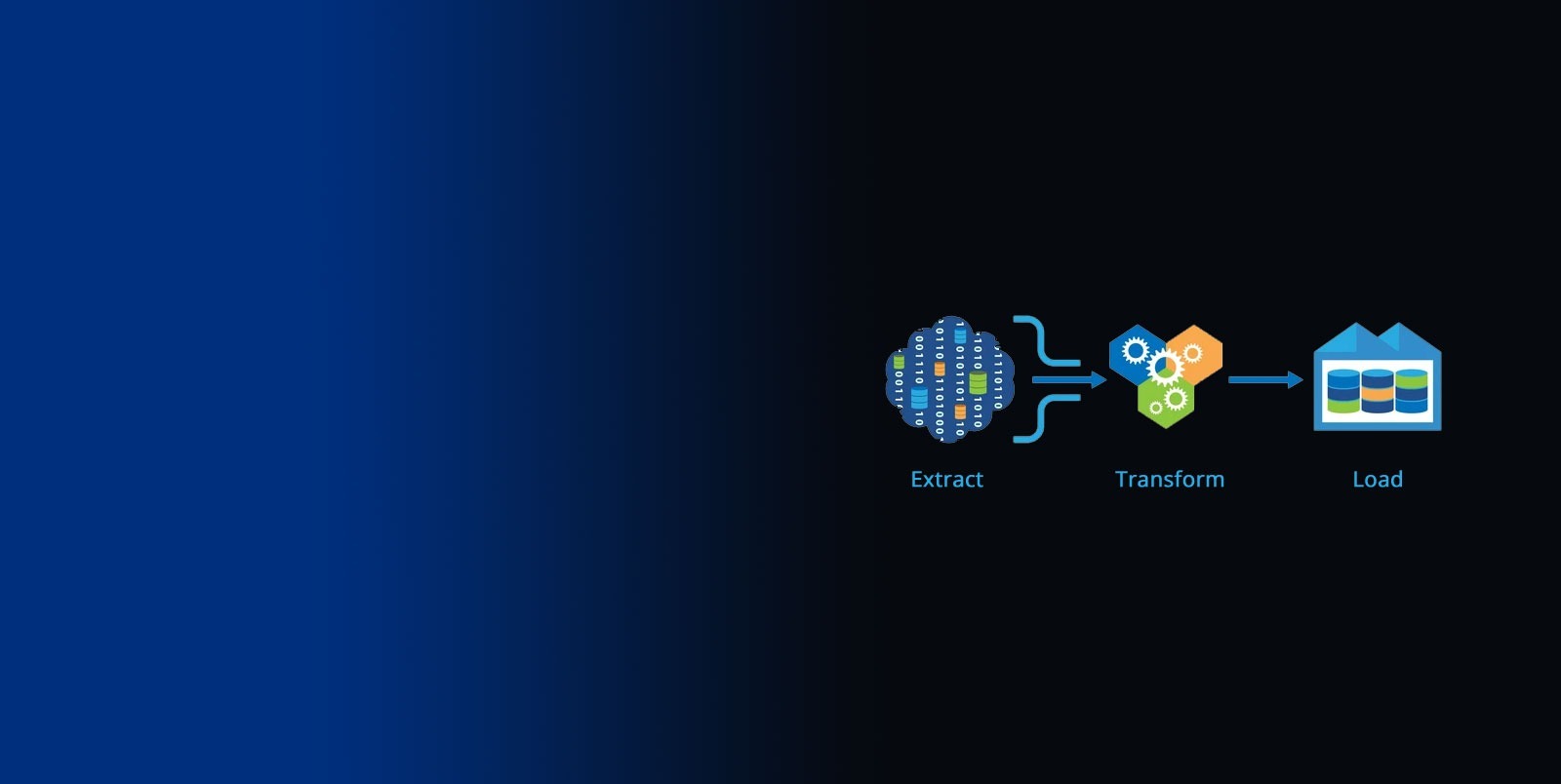
How Does an ETL Pipeline Work?
An ETL pipeline works by automating the extraction, transformation, and loading of data in a sequential manner. Each stage of the pipeline is crucial to ensuring that the data is correctly processed and meets the desired quality standards.
Step 1: Extract
The extraction phase involves collecting data from various sources, which can include databases, flat files, APIs, or cloud storage. The data is gathered in its raw form and then moved to a staging area where it awaits further processing. This step is crucial as it sets the foundation for the entire ETL process. The quality and completeness of the extracted data will determine the success of subsequent steps.
Step 2: Transform
In the transformation phase, the extracted data is processed and converted into a format suitable for analysis. This can involve data cleansing, where errors and inconsistencies are corrected, as well as data enrichment, where additional information is added to enhance the dataset. Common transformation operations include filtering, sorting, joining data from different sources, and aggregating data to provide a summarized view.
Step 3: Load
The final step in the ETL pipeline is loading the transformed data into the target system, which is often a data warehouse, data lake, or other storage solutions. This phase involves writing the processed data to the destination, where it can be accessed by business intelligence tools, data analysts, and other stakeholders. Ensuring that the data is loaded efficiently and accurately is crucial to maintaining the integrity of the entire ETL process.
Benefits of ETL Pipeline: Why ETL Pipelines are Essential?
ETL pipelines offer numerous benefits to organizations, making them an essential part of any data management strategy. Here are some of the key advantages:
- Data Integration: ETL pipelines allow for the seamless integration of data from multiple sources, ensuring that all relevant information is available in a single, consolidated view.
- Data Quality: By automating the transformation and cleansing of data, ETL pipelines help maintain high data quality, reducing errors and inconsistencies.
- Efficiency: Automation of data processes reduces manual intervention, saving time and resources while ensuring that data is processed faster.
- Scalability: ETL pipelines can handle increasing volumes of data as your business grows, ensuring that your data infrastructure remains robust and efficient.
- Decision-Making: With clean, well-processed data, businesses can make more informed decisions, leading to better outcomes and competitive advantages.
Components of an ETL Pipeline
An ETL pipeline is composed of several key components, each playing a vital role in the process:
- Data Sources: These are the origins of the data, including databases, APIs, flat files, and cloud storage.
- ETL Tools: Software or platforms that automate the ETL process, managing the extraction, transformation, and loading of data.
- Staging Area: A temporary storage location where data is held before it undergoes transformation.
- Transformation Logic: The set of rules and operations applied to the data to clean, enrich, and prepare it for analysis.
- Destination Systems: The final storage location for the transformed data, often a data warehouse or data lake.
- Monitoring and Logging: Tools and processes used to track the performance of the ETL pipeline, ensuring data accuracy and process efficiency.
Different Types of ETL Pipelines
ETL pipelines can vary depending on the specific needs and architecture of an organization. Here are some common types:
- Batch ETL Pipeline: Processes large volumes of data at scheduled intervals, typically used in traditional data warehousing.
- Real-Time ETL Pipeline: Processes data continuously as it is generated, suitable for applications requiring up-to-date information.
- Cloud-Based ETL Pipeline: Runs in cloud environments, offering scalability and flexibility.
- Open-Source ETL Pipeline: Built using open-source tools and technologies, allowing for customization and cost-effectiveness.
- Hybrid ETL Pipeline: Combines elements of batch and real-time processing, providing a balanced approach to data integration.
Characteristics of an ETL Pipeline
ETL pipelines have specific characteristics that define their effectiveness and efficiency:
- Automation: The ability to execute data processes without manual intervention.
- Scalability: The capacity to handle increasing volumes of data as business needs grow.
- Reliability: Ensures consistent and accurate data processing with minimal downtime.
- Flexibility: Can adapt to changes in data sources, transformation rules, or target systems.
- Performance: Optimized to process large datasets quickly and efficiently.
- Security: Protects sensitive data throughout the ETL process, ensuring compliance with data protection regulations.
Building an ETL Pipeline: Step-by-Step Guide
Building an ETL pipeline involves several steps, each critical to ensuring a successful implementation:
Step 1: Identify Data Sources: Determine the origins of the data you need to integrate, whether it’s databases, APIs, or flat files.
Step 2: Design the ETL Process: Define the extraction, transformation, and loading rules, taking into account data quality and business requirements.
Step 3: Choose ETL Tools: Select the software or platform that best fits your ETL needs, considering factors like scalability, ease of use, and cost.
Step 4: Implement the Pipeline: Set up the ETL pipeline according to your design, configuring each component to execute the process as planned.
Step 5: Test and Validate: Run test data through the pipeline to ensure it works as expected, identifying and fixing any issues.
Step 6: Monitor and Optimize: Continuously track the performance of the pipeline, making adjustments to improve efficiency and handle growing data volumes.
Related Blog: What is ETL Test Automation: A Guide to ETL Automation Testing
ETL Pipeline Best Practices
To ensure that your ETL pipeline operates effectively and efficiently, consider the following best practices:
- Data Quality Management: Regularly monitor and clean data to maintain high quality.
- Error Handling: Implement robust error handling and logging mechanisms to track and resolve issues quickly.
- Performance Optimization: Continuously optimize the pipeline to handle large datasets efficiently.
- Scalability Planning: Design the pipeline to scale with your business, ensuring it can handle increased data volumes.
- Security Measures: Implement strong security protocols to protect sensitive data throughout the ETL process.
Common Challenges in ETL Pipelines
While ETL pipelines offer numerous benefits, they also present certain challenges:
- Data Quality Issues: Ensuring that all data is clean, consistent, and free of errors can be challenging, especially with multiple data sources.
- Handling Large Volumes of Data: As data volumes grow, processing time and resource requirements can increase significantly.
- Integrating with Legacy Systems: Older systems may not easily integrate with modern ETL tools, requiring additional customization.
- Managing Changing Data Structures: As data sources evolve, the ETL pipeline must be updated to accommodate new structures and formats.
- Ensuring Real-Time Processing: Achieving real-time processing requires careful design and optimization, particularly for high-velocity data streams.
Top ETL Tools in the Industry
Several ETL tools are available in the market, each offering unique features and capabilities. Here are seven top ETL tools:
- Apache NiFi: An open-source tool for automating data flow between systems, supporting real-time processing.
- Talend: A powerful ETL platform that offers both open-source and enterprise solutions.
- Informatica PowerCenter: A widely used enterprise ETL tool known for its robust data integration capabilities.
- Microsoft SSIS: An ETL tool integrated with SQL Server, providing a comprehensive solution for data integration.
- AWS Glue: A cloud-based ETL service that automates data preparation and integration in the AWS ecosystem.
- Apache Airflow: An open-source workflow automation tool that can be used to manage ETL pipelines.
- Matillion: A cloud-native ETL tool designed for modern data warehouses like Snowflake, BigQuery, and Redshift.
Real-World ETL Pipeline Use Cases
ETL pipelines are used across various industries to solve data challenges and enable better decision-making. Here are some real-world use cases:
- Finance: ETL pipelines aggregate financial data from multiple systems to provide a consolidated view of company performance.
- Healthcare: ETL pipelines integrate patient data from various sources to create comprehensive health records for better care management.
- Retail: ETL pipelines process sales data from different channels to inform inventory management and marketing strategies.
- Telecommunications: ETL pipelines handle large volumes of call data records for real-time billing and customer service.
- Manufacturing: ETL pipelines integrate data from production lines and supply chains to optimize operations and reduce costs.
Future of ETL: Trends and Innovations
The field of ETL is constantly evolving, with new trends and innovations shaping its future. Here are some key trends:
- Cloud-Based ETL: As more businesses move to the cloud, cloud-native ETL solutions are becoming increasingly popular.
- Real-Time Data Processing: The demand for real-time insights is driving the adoption of real-time ETL pipelines.
- AI-Driven ETL: Artificial intelligence is being integrated into ETL tools to automate more complex data transformations.
- DataOps Integration: ETL is becoming a core component of DataOps, streamlining data workflows for faster delivery.
- Low-Code/No-Code ETL Tools: The rise of low-code and no-code platforms is making ETL more accessible to non-technical users.
FAQs about ETL Pipeline
To wrap up, let’s address some frequently asked questions about ETL pipelines:
Q1. How does ETL differ from ELT?
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are both data integration processes, but they differ in the order of operations. In ETL, data is transformed before loading into the destination system. In ELT, data is first loaded into the destination system, and then transformations are applied. ELT is often used in big data environments where the target system has the capacity to handle large-scale transformations.
Q2. What are some common challenges faced during ETL processes?
Some common challenges include maintaining data quality, handling large volumes of data, integrating with legacy systems, managing evolving data structures, and achieving real-time processing. These challenges require careful planning, robust tools, and continuous monitoring to overcome.
Q3. What industries commonly use ETL pipelines?
ETL pipelines are used across various industries, including finance, healthcare, retail, telecommunications, and manufacturing. They are essential for integrating data from multiple sources, ensuring accurate and timely insights for decision-making.
Q4. What are the common data sources for ETL pipelines?
Common data sources include relational databases, flat files (like CSVs), APIs, cloud storage, and even unstructured data like logs and documents. The choice of data sources depends on the specific needs and architecture of the organization.
Q5. What are some popular ETL tools available in the market?
Popular ETL tools include Apache NiFi, Talend, Informatica PowerCenter, Microsoft SSIS, AWS Glue, Apache Airflow, and Matillion. Each of these tools offers unique features and capabilities, catering to different business needs.
Conclusion
ETL pipelines are a critical component of modern data management, enabling organizations to efficiently process and integrate data from various sources. By understanding the workings, benefits, and challenges of ETL pipelines, businesses can better harness their data for informed decision-making. As technology continues to evolve, ETL pipelines will become even more powerful and essential in the data-driven landscape.
Optimize Your Data Flow with BuzzyBrains’ ETL Solutions!
Ready to take your data management to the next level? BuzzyBrains offers cutting-edge ETL solutions that can help you streamline your data processes, ensuring that your business has access to the accurate and timely information it needs to succeed. Contact us today to learn how our ETL tools can transform your data operations!